
Real-time stock availability and delivery date promising can represent a significant structural bottleneck when operating high-velocity consumer channels on top of legacy, monolithic ERP architectures. Under sustained peak demand, customer-facing interfaces, product detail pages, and checkout APIs continuously check inventory states to show accurate availability badges or delivery promises.
Running these calculations directly within core ERP databases can consume significant compute resources and introduce latency, risking delayed responses, connection drops, and lost digital sales. To mitigate these risks, enterprise leaders should deconstruct the mechanics of database contention, draw lessons from verified web-scale platform challenges, and decouple complex delivery promising calculations from the transactional core.
The Core Problem: Inventory Lookup vs. Dynamic Delivery Promising
In modern omnichannel commerce, we should distinguish between a simple stock lookup and a dynamic delivery promise. Displaying a basic inventory status, such as a binary “In-Stock” green badge on a product detail page, is a relatively low-cost operation. Many retailers successfully cache these binary states at the CDN or edge database layer to prevent catalog browsing from ever hitting the ERP.
The real scalability challenge occurs when a platform attempts to calculate a precise delivery promise, such as an Estimated Time of Arrival (ETA). To answer the question of when an item can be delivered to a specific customer, an order promising engine cannot rely on a single, static value. Instead, the system typically must dynamically calculate the intersection of multiple relational tables, evaluating active physical balances, inbound supply pipelines, and complex logistics constraints, such as fulfillment nodes, regional carrier capabilities, shipping cutoff times, transit calendars, and localized allocation rules.
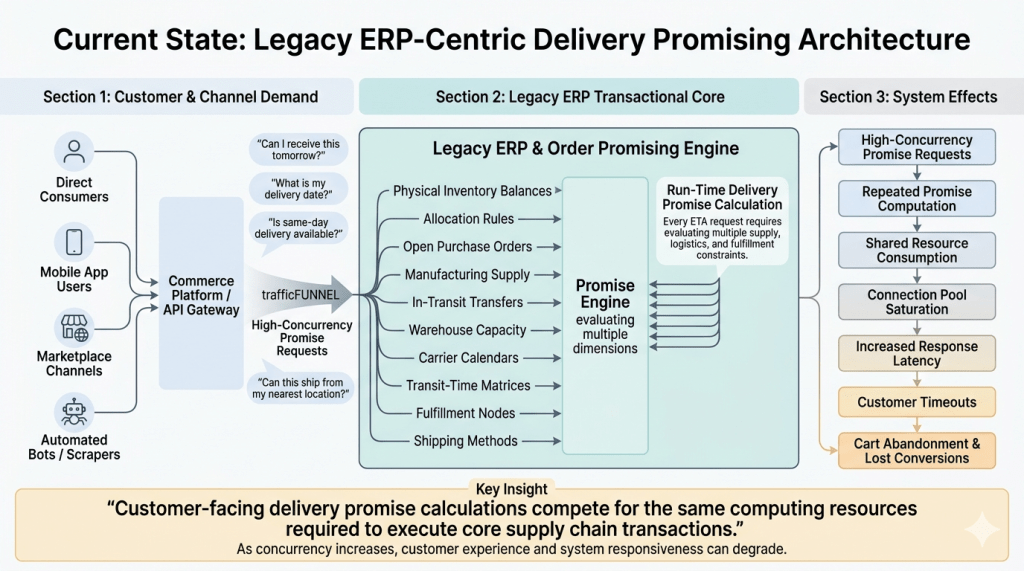
Given this calculation involves a highly combinatorial matrix, mapping SKUs to destination ZIP codes, warehouses, and carrier service levels, it cannot be easily cached as flat data. In poorly optimized architectures, customer checkout streams may trigger these heavy calculations dynamically. Unlike simple stock lookups, calculating these multi-variable promises requires substantial database processing power. When highly concurrent query traffic is directed to the core transactional database, it directly competes for CPU and memory cycles with critical write operations, such as ship confirmations and warehouse receipts. As transactional latency increases under sustained load, connection pools can saturate, potentially leading to dropped API requests and shopping cart abandonment.
Drawing Parallels: The Concurrency-Driven Query Surge
The classic B2B Allocation Bullwhip is a well-established supply chain phenomenon where small shifts in retail demand amplify into massive supply distortions as orders move upstream to manufacturers. In high-velocity B2C digital commerce, we can observe a clear architectural analogy: the concurrency-driven query surge.
This surge is frequently powered by engineered scarcity, such as high-demand product drops, flash sales, or limited-quantity seasonal launches. When consumers and automated checkout networks anticipate highly rationed inventory, they can generate massive, concentrated traffic spikes. Automated scraping programs reload product pages every few milliseconds to detect inventory shifts, creating an exponential wave of phantom query demand.
Because these scarcity drops concentrate massive volume on a small set of highly coveted items, the query load of a global business is funneled into a small set of inventory records, indexes, or database cache keys. Without a decoupled promising layer, these requests may repeatedly trigger expensive relational database calculations. This behavior can saturate the transactional database thread pool, causing processing latency to spike and potentially degrading customer-facing checkout performance.
Real-World Proof Points & Analyst Perspectives
This systemic vulnerability has been heavily documented across high-traffic digital platforms, drawing direct scrutiny from leading market analysts.
High-Profile Failure Case Studies
The Ticketmaster “Eras Tour” Bottleneck (November 2022): As documented in the official Ticketmaster business statement released on November 17, 2022 (“Taylor Swift The Eras Tour Onsale Explained”), Ticketmaster’s ticketing system was overwhelmed by an unprecedented surge of 3.5 billion total system requests. High volumes of bot traffic and uninvited users swamped the platform. Ticketmaster’s official review noted:
“The staging of this tour required validating fan status via passcodes. The massive traffic, combined with an unprecedented number of bot attacks, created excessive queue times and slowed site performance to stabilize systems.”
While this incident involved transaction queue saturation rather than a standard SCM checkout, it illustrates a critical architectural parallel: monolithic, tightly coupled validation queues are highly vulnerable to sudden concurrency spikes on shared record states.
The PS5 Online Retail Bot Invasions (2020–2021): During major retail PS5 restocks, online storefronts repeatedly experienced severe performance degradation. As reported by the New York Times in an article dated November 27, 2021 (“How ‘Grinch Bots’ Are Stealing Your Holiday Shopping Plans”), automated shopping bots continuously scraped and reloaded retail pages to secure inventory:
“Cybersecurity firms reported that automated programs, known as bots, were reloading retail pages every few milliseconds to detect and buy consoles before humans could click.”
This extreme scraping behavior demonstrates the scale of phantom query demand that retail systems must absorb, highlighting why on-the-fly database calculations represent a critical point of vulnerability.
The Nike SNKRS Platform Shift: Nike’s early sneaker drops frequently encountered scalability limits when utilizing traditional, monolithic ERP inventory ledgers. Bot-driven concurrency spikes checking product availability caused database bottlenecks, forcing an architectural transition. As documented in subsequent AWS SCM engineering publications:
“By decoupling customer-facing inventory check services from our enterprise resource planning systems and deploying on a cloud-native microservices architecture, we achieved the ability to handle millions of transactions per second during high-velocity global product drops.”
What the Analysts Say
Gartner’s Composable SCM Strategy: In their strategic guidelines on modular enterprise design published on June 3, 2020 (“Gartner Says by 2023, Organizations That Have Adopted a Composable Approach Will Outpace Competition”), Gartner highlights the value of modularity, orchestration, and autonomy to help businesses become more resilient:
“By 2023, organizations that have adopted a composable approach will outpace competition by 80% in the speed of new feature implementation. Monolithic ERP backbones must be decoupled to prevent system rigidity during digital demand peaks.”
McKinsey & Company on eCommerce Friction: In their retail insights report published on July 23, 2020 (“The Quickening: How COVID-19 Is Accelerating Digital Commerce”), McKinsey notes that the pandemic accelerated digital adoption by several years, making online user experience a critical competitive battleground:
“We have covered 10 years of e-commerce penetration in just 90 days. In this accelerated landscape, transaction latency and check failures act as friction points that prompt instant shopping cart abandonment.”
The common thread running through these real-world events and analyst assessments is clear: monolithic, tightly coupled architectures are more susceptible to performance degradation when parallel, high-frequency queries focus on a small set of shared states. Forcing a transactional core to dynamically calculate state under web-scale check traffic can starve critical resources under sustained load. The systemic failure profiles observed across these diverse industries represent the exact same risk that enterprises face when they tie customer-facing delivery promising calculations directly to an ERP database of record. At large scale, many organizations decouple availability and promising calculations from transactional writes.
The Proposed Architecture: Decoupled Availability Promising
To survive high-velocity B2C drops and peak holiday runs, architects are increasingly moving away from synchronous, dynamic database calculations.
The Architectural Transition: Matching Legacy Intelligence at the Edge
A comprehensive availability check goes far beyond evaluating basic physical inventory. It must evaluate complex channel allocations, dynamic borrowing rules, regional transit matrices, shipping method options, carrier pickup calendars, and predictable disruptions like public holidays. In modern omnichannel environments, these challenges are heavily compounded by fulfillment sources that span regional warehouses, local retail stores, and third-party logistics nodes, serving geographically spread destinations across millions of ZIP codes via multiple delivery service levels (such as air, road, same-day, or next-day).
Traditional order promising systems, such as legacy Global Order Promising (GOP) engines, are natively strong at executing these highly complex, multi-variable logic paths because they operate on direct, relational access to the entire enterprise database of record. Consequently, any decentralized microservice architecture designed to offload availability checks typically needs to replicate or externalize key promising capabilities outside the ERP transaction path without re-introducing the relational database row contention and table-join latencies that compromise the core.
Foundations of the Decoupled Architecture
To achieve low-latency response times, we propose an alternative, decoupled architecture built upon two core system principles:
- In-Memory Snapshots (Powered by Redis): The customer-facing check interface must bypass the analytical overhead of relational table lookups entirely. Operating on an in-memory cache layer, typically powered by Redis, is like relying on SCM muscle memory or instinct; the system immediately serves pre-computed stock answers directly from memory, rather than performing a conscious, resource-heavy SQL database calculation on a physical disk. Most key-based cache lookups execute with near-constant-time performance, delivering results typically in microseconds to low milliseconds at the database layer. This snapshot pattern is highly modular and can be deployed independently across separate transactional data segments (such as stock balances, allocation pools, or shipping matrices) to isolate check queries from disk-bound relational databases.
- Asynchronous Event-Based Ingestion (Powered by Apache Kafka): To ensure our in-memory cache remains live and fresh, the architecture must ingest data through an asynchronous, event-driven data pipeline. When physical transactions occur (such as a warehouse receipt, a stock transfer, or an order shipment), the system of record emits a lightweight event. These events are captured in near real-time by a distributed event-streaming backbone like Apache Kafka, processed in the background, and applied directly to update the cache snapshots. Given that modern ERP systems are increasingly moving to SaaS models (walled gardens), extracting these events requires a highly pragmatic, multi-tiered ingestion strategy:
- High-velocity transactions (live inventory movements, shipments, and order bookings) often leverage CDC technologies such as Oracle GoldenGate, Debezium, or platform-native event streams to capture commits with minimal latency and zero application overhead.
- Lower-velocity operational changes (such as procurement approvals or purchase order status updates) can rely on native, application-level business events.
- Slowly changing configuration metadata (such as allocation rules, public holiday calendars, and regional transit-time matrices) are best updated through scheduled nightly batch pipelines.
This decoupled approach is not merely a theoretical construct; it is the exact design paradigm utilized by leading enterprise software suites to scale. For example, modern cloud-native SCM architectures, such as SAP’s advanced ATP (aATP) or Oracle Cloud’s Global Order Promising (GOP) engine, utilize memory-optimized processing and architectural isolation from core transaction workloads. Even when they leverage direct, read-only database connections to pull on-hand balances, they do so using non-blocking patterns, such as multi-version concurrency control (MVCC), to ensure that customer-facing promising queries typically avoid imposing transactional row locks or degrading performance on the core ERP.
Resolving Omnichannel Complexity at the Edge
- Channel Allocations and Priority Borrowing: To handle segment-specific allocations (such as reserving 60% of stock for Direct, 20% for Retail, and 15% for Distributors) alongside dynamic borrowing rules, we apply our in-memory snapshot principle by caching channel allocation balances as distinct fields within a unified record. When an availability check occurs, the API edge layer executes a lightweight, single-threaded processing script directly inside the cache’s local memory space. This script evaluates the allocated balances and processes the pre-compiled borrowing sequence with very low latency, bypassing transactional database tables entirely.
- The ZIP Code and Transit Time Matrix: To prevent a combinatorial data explosion of SKUs, shipping methods, and millions of destination ZIP codes in cache, we apply the architectural principle of Separation of Concerns. We split the availability check into two independent, concurrent in-memory reads at the API gateway edge. The first read pulls active SKU balances per warehouse location (utilizing Principle 1), while the second read pulls static transit day zones for the customer’s ZIP code. The API gateway compiles these two lightweight states in memory, serving accurate, localized delivery promises in low-millisecond response times.
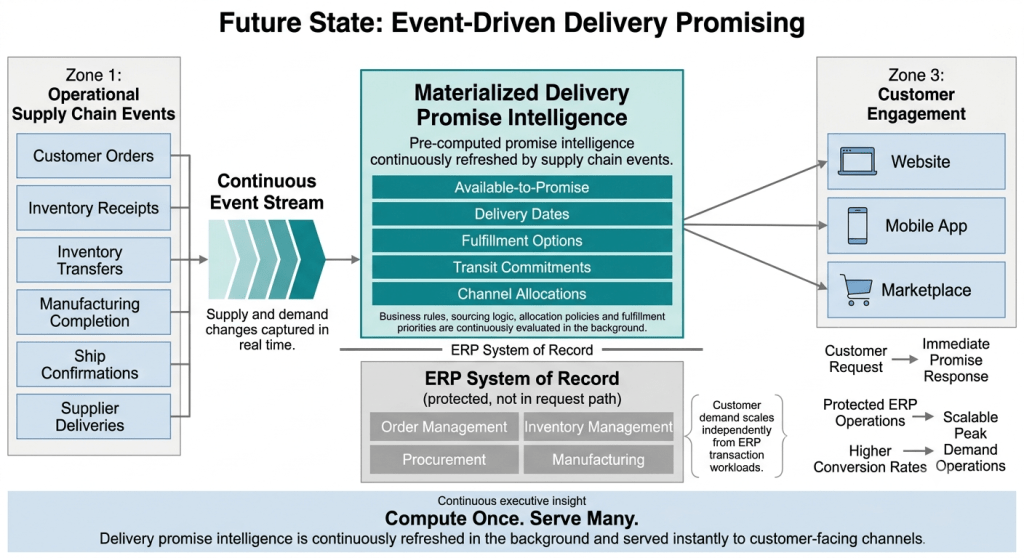
Where Has This Been Done Before?
To prove that event-driven materialized promising is a commercially viable model rather than vaporware, SCM architects can look to major global retailers who have successfully decoupled high-volume checkout paths from legacy ERP systems of record:
Target’s Event-Driven Inventory Transformation
To handle the massive, concurrent transaction spikes of the holiday shopping season, Target migrated its digital cart and inventory systems away from centralized relational databases. As documented in The Wall Street Journal (dated October 23, 2018, “How Target’s IT Team Survived the Holidays”):
“Target moved its digital shopping systems off a monolithic database to a distributed, event-driven architecture. By processing inventory changes as asynchronous event streams rather than run-time database queries, the retailer eliminated the database bottlenecks that historically caused site crashes on Black Friday.”
Adidas’ Decoupled Inventory Promising Engine
During limited-edition sneaker launches, Adidas experienced massive traffic spikes that threatened to overwhelm its core SAP ERP system. As detailed in InfoQ Technical Case Studies (dated March 12, 2019, “Designing Event-Driven Microservices at Adidas”):
“To protect our monolithic ERP from crashing during high-volume product drops, we decoupled the inventory checking logic entirely. By streaming inventory allocations through Kafka into an in-memory cache, we served millions of concurrent stock queries without exposing our core system of record to any traffic spikes.”
Strategic Takeaways
- Shift the Computational Burden: Do not force your transactional database of record to perform run-time analytical calculations under heavy consumer traffic.
- Leverage In-Memory State: Pre-compute inventory states and borrowing rules asynchronously. Expose them via a high-speed, key-value in-memory layer to support low-latency customer experiences.
- Decouple the Core: Keep your ERP quiet. Minimize unnecessary real-time dependency on your core ERP during peak traffic. Use asynchronous, log-structured pipelines to bridge the physical supply chain with customer-facing engagement layers, ensuring your systems are resilient to the B2C concurrency-driven query surge.
The Path Forward
The modern customer experience is built entirely on the expectation of instant responsiveness. In high-concurrency environments, sticking to legacy, synchronous availability and delivery date checks directly within the ERP core can represent a meaningful risk to revenue, retention, and customer experience under peak demand conditions.
To thrive under the weight of modern consumer demand, organizations must treat SCM technology not as a static transactional repository, but as an active engine of business enablement. Enterprise architects and technology leaders must take the initiative to proactively audit their current transactional dependency profiles.
Is your enterprise platform still struggling with transactional contention and scalability bottlenecks during peak sales, or have you empowered your supply chain with the speed of decoupled promising? The transition from legacy monolithic configurations to high-throughput, event-driven architectures is increasingly distinguishing modern digital commerce platforms from traditional architectures.
About the Author: Mukund Sridharan is an SCM Transformation Advisor and Industry Fellow with over two decades of experience designing high-concurrency data flows and enterprise systems strategies for global telecom, manufacturing, and life sciences networks.
“`
